Whilst doing some design work today for a customer project I realised there are a set of principals I try and adhere to when creating SQL Server Integration Services packages. The list is no doubt incomplete but this is what I have so far.
Minimise IO
This is a general data processing principal. Usually disk and, to a lesser extent, network performance determine the overall processing speed. Reducing the amount of IO in a solution will therefore increase performance.
Solutions that consist of multiple read-process-write steps should be redesigned into a single read-process-process-process-write step.
Prefer Sequential IO to Random IO
Disks perform at their best when sequentially reading or writing large chunks of data. Random IO (and poor performance) manifests when procedural style programming occurs - signs to look out for are SQL statements modifying/returning only few rows but being executed repeatedly.
Watch out for hidden random IO - for example, if you are reading from one table and writing to another in a sequential manor then disk access will still be random if both tables are stored on the same spindles.
Avoid data flow components that pool data
Data flow components work on batches of data called buffers. In most instances buffers are modified in place and passed down stream. Some components, such as “Sort” cannot process data like this and effectively hang on to buffers until the entire data stream is in memory (or spooled to disk in low memory situations). This increased memory pressure will affect performance.
Sometimes SQL is the better solution
Whilst the SSIS data flow has lots of useful and flexible components, it is sometimes more efficient to perform the equivalent processing in a SQL batch. SQL Server is extremely good at sorting, grouping and data manipulation (insert, update, delete) so it is unlikely you will match it for raw performance on a single read-process-write step.
SSIS does not handle hierarchical data well
Integration Services is a tabular data processing system. Buffers are tabular and the components and associated APIs are tabular. Consequently it is difficult to process hierarchical data such as the contents of an XML document. There is an XML source component but it’s output is a collection of tabular data streams that need to joined to make sense.
Execute SSIS close to where you wish to write your data
Reading data is relatively easy and possible from a wide variety of locations. Writing data, on the other hand, can involve complex locking and other issues which are difficult to optimise on a network protocol. In particular when writing data to a local SQL Server instance, SSIS automatically used the Shared Memory transport for direct inter-process transfer.
It’s very difficult to do this anyway but worth mentioning that SSIS gets it’s stellar performance from being able to setup a data flow at runtime safe in the knowledge that buffers are of a fixed format and component dependencies will not change.
The only time this is acceptable is when you need to build a custom data flow programmatically. You should use the SSIS API’s and not attempt to write the package XML directly.


 First drop a “Script Component” onto your Data Flow.
First drop a “Script Component” onto your Data Flow.
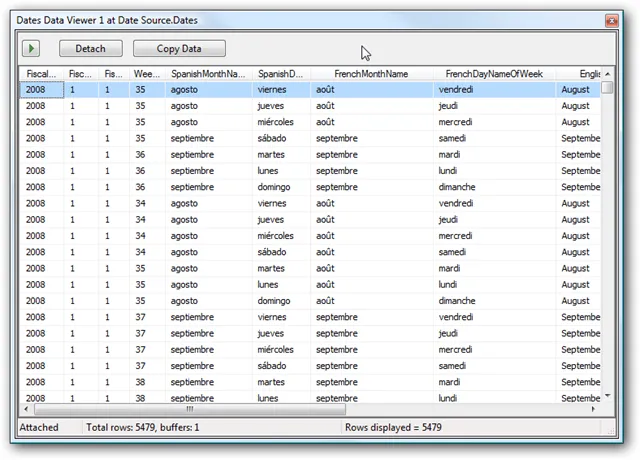 From here you can manipulate the data, and pipe it to your dimension table from within the pipeline.
From here you can manipulate the data, and pipe it to your dimension table from within the pipeline.