

Latest links for easy consumption over the May long weekends – I missed out on March so have dropped some of the less interesting ones to keep the list short.
Organisational Behaviour
Programmers, Teach Non-Geeks The True Cost of Interruptions – a simple way to show to your boss how drive-by-management kills programmer productivity. Also work reading Maker’s Schedule, Manager’s Schedule which highlights the differences. If this is still a problem then this notice might be your only solution…
The Death Of Expertise – The Dunning-Kruger effect is often strong in semi-technical managers especially in industries where confidence plays a large part in success such as finance. This article discusses some of the problems related to treating all opinions as equal and ignoring experts.
Save Your Software from the Start: Overcoming Skewed Thinking in the Project Planning Stage – Very simply, why we always underestimate the true complexity and cost of a project plus some tools to help overcome these psychological effects.
Why Good Managers Are So Rare - Gallup finds that companies fail to choose the candidate with the right talent for the job 82% of the time. Managers account for at least 70% of variance in employee engagement scores across business units.
I Give Up: Extroverted Barbarians at the Gates – Anyone remember the “perpendicular transparent red lines” video doing the rounds? This is an on-the-nail deconstruction of what is happening and why it happens. If you are an introvert then this other post might feel very familiar to you.
Agile
Coconut Headphones: Why Agile Has Failed – A rant about how modern agile methodologies seem to only consist of management practises. Take note of the end points to being successful.
The death of agile? – Additional comment on the above.
Writing User Stories for Back-end Systems – The real functionality a user sees in a business intelligence project is quite small and can easily be described in a few words. This makes breaking up user stories into sprint sized chunks hard. This article gives some great advice that can be translated to BI projects.
Design Your Agile Project, Part 1 – So how do you pick the right kind of agile project? When should you use Kanban and when should you use Scrum? How is the business side of equation handled? Also Part 2, Part 3, and Part 4.
Large Agile Framework Appropriate for Big, Lumbering Enterprises – A perfect solution to doing agile in finance organisations (wink). Love the concept of ‘Pair Managing’.
Metrics that matter with evidence-based management – Its long but Martin does a great job looking at lots of the metrics in use today, why their use is limited and a far better approach to designing metrics that really help.
Databases
Is ETL Development doomed? – “Long term, the demand for ETL skills will decline”. The demand will mutate into one for more abstract ETL capabilities.
Testing
Intro to Unit Testing 9: Tips and Tricks – A handy list of tips that can make maintaining unit test code a little easier.
FsCheck + XUnit = The Bomb – Even if you write code in C# it may be wise to think about writing unit tests in F# since the code is more concise, easier to read and with FxCheck can find things you might not.
Data Visualization
5 Tips to Good Vizzin’ – Should be required reading for anyone who is thinking about creating dashboards in Tableau.
A Natural Approach to Analytics – This explains why using tools such as Tableau for largely static dashboards is a waste of time. Users need to interact with the data in a way they cannot do when relegated to dashboard consumers.
Big Data/Hadoop
Modern Financial Services Architectures Built with Hadoop – Hortonworks looks at big data in financial services.
Beyond hadoop: fast queries from big data – I think Hadoop might be catching up here but it is still a bit of an elephant compared to SQL Server/Oracle etc when it comes to raw query performance.
Don’t understand Big Data? Blame your genes! – 5 common errors for dealing with big data.
The Parable of Google Flu: Traps in Big Data Analysis – Big data answers are not always correct. This paper looks at some of the pitfalls.
No, Hadoop Isn’t Going To Replace Your Data Warehouse – More thoughts on modern data architectures and hybrid transactional/analytical processing.
Discuss this on Twitter or LinkedIn
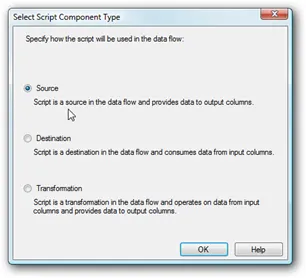 First drop a “Script Component” onto your Data Flow.
First drop a “Script Component” onto your Data Flow.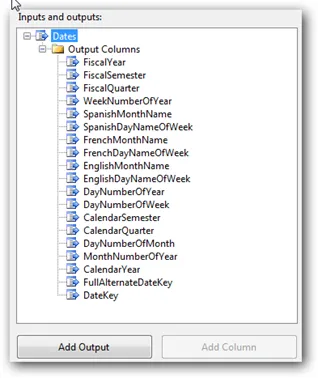
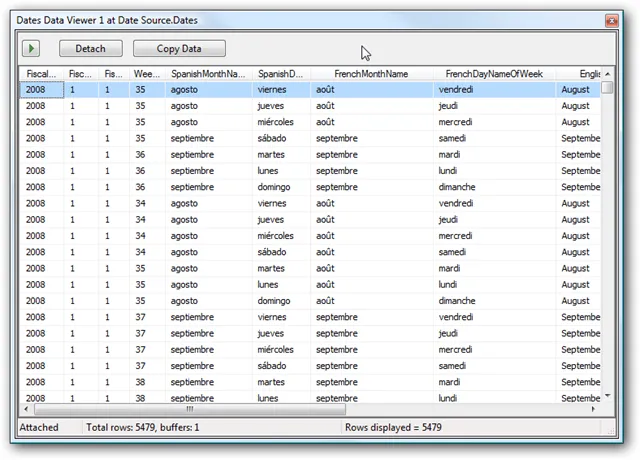 From here you can manipulate the data, and pipe it to your dimension table from within the pipeline.
From here you can manipulate the data, and pipe it to your dimension table from within the pipeline.